Data Routing refers to the process by which you apply stream rules and pipeline rules to filter and transform log data once it is ingested by Graylog and the selection of specific destinations in which to store all or some subsets of this data. Routing is applied at the level of a stream, and so Data Routing configuration begins by identifying the specific stream you wish to filter, enrich, and route.
Configure Data Routing for a Stream
To apply Data Routing on a stream:
-
Select the Streams tab from the top-level menu.
-
Locate the specific stream for which you want to specify data routing actions.
-
Select the Data Routing button for that stream.
Now, Graylog prompts you through three different steps so that you can specify how and where your log data is routed through the Graylog service.
Intake
At this stage you can apply specific stream rules that allow you to determine what data is moved from an input into the selected stream. To add a new stream rule, select Create Rule. For more information on creating stream rules, see the documentation on stream rule creation.
This stage also displays any pipeline rules attached to other streams that route messages into the current stream. The table view shows the name of the rule, the source pipeline, and the source streams. Select the rule name to view details of the rule on the Manage rules page (System > Pipelines > Manage rules). Select the pipeline link to view the detail page for the pipeline itself. These pages allow you to make updates to the pipeline rules or pipelines, unless the specific entity is system-managed. For more information on creating pipeline rules, see the documentation on pipeline rule creation.
Processing
Here the specific pipelines attached to the stream are displayed, and you can apply additional pipelines to further filter your logs by selecting Edit pipelines connection.
Additionally, if this stream was created as part of an Illuminate content pack, you are notified that data processing rules might already apply and are processed prior to any subsequent pipeline rules you create.
Add Pipelines to a Stream
To add pipeline processing to this stream:
-
Select Edit pipelines connection.
-
In the new menu, select the pipeline you wish to apply to the stream.
-
Click Update connections to apply the pipeline.
To create a new pipeline that you wish to add to the stream, see the Pipelines documentation.
Destinations
Finally, you are prompted to determine the destination or destinations into which you want your log data sent after processing. These destinations are highly customizable, meaning that you can send either some portion or all of the data routed by a stream to one or more destinations depending on how you configure the Data Routing process. See the following sections for more details on setting up destinations.
Configure Data Routing Destinations
In setting up a destination or multiple destinations for logs in this stream, consider the following factors:
-
What is the purpose in routing or storing this data, and what destination best serves that purpose?
-
What specific data should be routed to which destination?
-
What are the conditions or rules by which you can filter out these data sets for your intended destinations?
To begin to answer these questions, first consider the different destinations offered and their various purposes and capabilities.
Determine a Destination
Routing your logs into a specific destination is a key step in the process of moving logs through Graylog. Data Routing offers three destination types. Your destination choices depend on your goals and the purposes for your data:
-
Data Lakes: You can opt to store your data in a Data Lake, which is housed by Amazon S3 or your preferred network storage solution. This option is generally a lower-cost solution for data that you wish to keep but do not currently want to search or analyze in Graylog. Note that this is an Enterprise-only feature. See Data Lakes for more information on this destination type.
-
OpenSearch Indices: You can route some or all of the data to index sets utilizing the Graylog index model. You can choose this destination for specific log data you want to keep optimized for quick search, analysis, alerts, event management, and more, depending on where you write the data.
-
Outputs: You can also route your data to an output, which allows you to forward the data to an external system or service, like another Graylog instance.
Set a Destination
To enable a specific destination for this stream, select the toggle switch next to the destination type. If the destination cannot be enabled, you are not able to toggle this switch on and might receive an error message. For example, if a Data Lake has not been configured, you cannot select Data Lake as a destination, and a message appears stating that no active Data Lake is available.
You can enable more than one destination for your stream. For example, you may choose to send the same set of data (or all data) to multiple destinations, or you may choose to filter your data, sending a subset of log data to one destination and a different subset to a different destination. You determine what data is sent to what destination by applying filter rules, as described in the following section.
Filter Your Logs
For each available destination, you can apply filter rules that determine what log data is sent to this destination. Multiple filter rules can be applied to the same destination depending on how you wish to filter your data.
Create a New Filter Rule
To create a new filter rule, select the expansion arrow to the right of your destination type, then click Create rule in the Filter Rules section. Here, you are presented with the Create Filter Rule wizard.

Filter rules are based on conditions that define parameter values that can apply to a log message, like a specific source input or whether or not a specific field is null. When you build a filter rule, you must apply at least one condition to the rule, and you can use multiple conditions to create a rule that filters out log data based on a variety of factors.
Data Routing Use Case Scenario
Jesse is a security analyst at a large organization and is responsible for monitoring and managing logs from multiple systems, devices, and applications. He is particularly interested in ensuring that critical and high-priority logs are available for analysis and remediation immediately while low-priority logs are stored for future analysis in a Data Lake.
To begin to do so, Jesse has configured a syslog input, and he wants to use it to pull in log data exclusively from key network routers. He wants to route these logs through a dedicated stream, enrich these logs with a pipeline, and send these logs to two key destinations: a Data Lake and a specific index set.
He knows that the logs from this input are categorized by four different levels of severity:
-
Error (critical logs that need immediate attention)
-
Warning (logs that indicate potential issues)
-
Information (logs that provide general system information)
-
Debug (low-level logs used for troubleshooting)
Streams
Once Jess has configured the input and log data is flowing from the designated log sources, Jesse decides to create a stream dedicated to routing this log data. He titles this stream "Network Router Logs," and he selects the Data Routing function to begin the process of funneling his logs through Graylog.
At the Intake step, Jesse creates a stream rule that specifies all log messages from the syslog input be directed to this stream. For the field, he selects gl2_source_input, and indicates that the type should match exactly. For the value, he enters the input ID found next to the title of the input on the System > Inputs page.
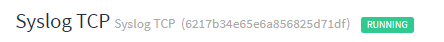
For this example, the input ID value he provides is 6217b34e65e6a85625d71df.
To complete the rule creation process, he selects Create Rule. Now all log data from this input will be routed to the stream when the stream is enabled.
Pipelines
Now, Jesse wants to add a processing pipeline to his stream to enrich the log data funneled by this stream. He knows that the input is collecting log data from multiple network routers, and he wants to create a field name that labels a specific router by its location so that he can later create a widget that displays log data for that specific router.
So, he navigates to the pipeline rule builder interface and creates a new pipeline containing the rule stating that, when the message contains error code ASA-1-101003, then Graylog should apply the field name warehouse_router to the message. He then saves the rule to the pipeline and titles the pipeline "Router Field Name."
In the Processing step of setting up data routing, Jesse can now select the pipeline "Router Field Name" and apply it to the stream.
Destinations
Finally, Jesse wants to route these logs to two destinations: the index set attached to the stream and a Data Lake.
Index Set
Jesse wants to be able to configure alerts for logs with a higher severity level, including error and warning logs, so these logs need to be routed to a dedicated index set, making them available for search and analysis functions. Jesse begins by enabling the Index Set destination, and he selects Create rule so that he can add the filter conditions for filtering logs appropriately into this destination.
After titling the rule and providing a description, Jesse wants to add a condition to the rule. Because filter rules are exclusionary, he knows that he wants to filter out the logs that do not have a high severity level, like information and debug message types. So, he selects Add condition and Field contains. The field he wants to run the rule against is message, and he wants to exclude information. He then selects Create to complete the rule. To also filter against debug messages, he creates another rule with the same set of conditions except that he adds debug as the substring for this rule.
Now, high priority logs are written directly to his search backend so that he can perform search and analysis functions against them.
Data Lake
Jesse wants to store the low priority logs in a Data Lake so that they can be retrieved at a later date if needed. He enables Data Lake as a destination, which is available as he has already set up a backend data storage solution. Much like the filter rules he created for his selected index set, he must now also apply filter rules to the Data Lake that determine how log data should be routed to his destination.
At present, he only wants to store high-value logs in his search backend and not in the Data Lake, so he needs to set up exclusionary conditions that filter out those logs from being routed to the Data Lake. He begins by selecting Create rule. Then, he selects Add condition and Field contains. As in the previous steps, the field he wants to run the rule against is message, but this time he wants to exclude error. He then selects Create to complete the rule. Finally, he creates one more rule with the same set of conditions except that he adds warning as the substring.
Conclusion
As a final step, once the data routing process is complete, Jesse makes sure that the stream is active as indicated by the status Running on the Streams page. Now, log data is flowing from his syslog input through the rules and filters applied to the stream and into their appropriate destinations for his use.
