Graylog System Architecture
Building an efficient Graylog on-premises deployment is essential for managing log data at scale while ensuring performance, reliability, and cost-effectiveness. As log volumes grow, proper planning becomes crucial to avoid bottlenecks, support scalability, and meet compliance requirements. This article provides a structured approach to designing a Graylog deployment according to standardized models that aligns with your organization's needs.
In this article we will explore different deployment models, key infrastructure components, and best practices for optimizing storage, computing resources, and system performance.
Prerequisites
Before proceeding, ensure that the following prerequisites are met:
-
Familiarity with the required and optional components of the Graylog stack is required to determine your optimal build.
-
A basic understanding of storage options (e.g. SSD vs. HDD) and how IOPS affects log processing speed will aid in your assessment of the architecture recommended.
Highlights
The following highlights provide a summary of the key takeaways from this article:
-
Choose high-IOPS storage solutions, such as SSDs, to ensure efficient log ingestion, indexing, and retrieval, minimizing latency and improving search performance.
-
Select and build an architecture that can grow with your log volume and processing needs, considering factors such as cluster expansion, load balancing, and resource allocation.
-
Establish a log retention policy that balances compliance requirements with available storage capacity, ensuring you meet regulatory obligations while maintaining cost efficiency.
Size Estimator
To determine the required architecture, hardware, storage, and other resource specifications for your deployment, leveraging Graylog's size estimator is a helpful first step. This tool helps estimate system requirements based on your number of users and retention policies or by estimated daily log volume, providing general recommendations for deploying a reliable and scalable Graylog environment.
Estimate Based on Users and Retention
First, determine the total estimated number of users expected to access the network that Graylog will monitor.
Next, estimate the number of days that you wish for logs to remain in hot search.
Estimate Based on Daily Log Volume
Estimate your total expected daily log volume:
Recommended Architecture:
Default Ports
Graylog relies on specific ports to communicate across its components. Below is a summary of the default network ports used:
| Destination | Port |
Source |
Purpose |
|---|---|---|---|
| Graylog | tcp/9000 | Browser | Graylog web interface/API |
| OpenSearch | tcp/9200 | Graylog | Graylog communication with OpenSearch |
| MongoDB | tcp/27017 | Graylog | Metadata storage |
| Data Node | tcp/9300 | Graylog | Log data storage |
| Sidecar | tcp/5044 | Log collectors | Shipping logs to Graylog |
Understand Your Deployment Architecture
Graylog generally recommends three on-premises deployment models for your consideration:
Core Deployment
A Core Graylog deployment is a standalone setup where all components of the Graylog stack (Graylog, Data Node, and MongoDB) reside in two servers. This architecture is ideal for small-scale environments or testing purposes, providing simplicity and ease of setup at the cost of scalability and redundancy.
The diagram below provides a visual representation of this basic architectural model, demonstrating its components, data flow, resource allocation, hardware, and storage requirements.

Some of the key characteristics of a Core deployment include:
-
Ease of Design: Simplified setup and maintenance.
-
Value: Cost-effectiveness for limited log volumes and minimal user interaction.
-
Application: Best suited for small-scale production environments, non-critical use cases, proof-of-concept projects, or lab environments.
Deployment Considerations
A core deployment is quick to implement but lacks fault tolerance and scalability. If either node goes offline, log ingestion and analysis will be interrupted.
Message Storage
Graylog has two key components that require additional storage configuration: the message journal and Data Node index storage.
Message Journal
The message journal temporarily holds incoming messages before they are processed. By default, it is configured to store up to 5GB of messages or 12 hours of data.
For optimal performance, it is recommended to store the message journal on high-speed storage, such as solid state drives (SSDs), and allocate storage capacity equivalent to 3 to 5 times your daily data ingestion to ensure efficient processing and log retention.
For more details on configuring the message journal, refer to the Graylog Server Configuration documentation.
Data Node Index Storage
The Data Node index storage is where hot-tier message data is stored. It must have enough capacity to store logs for the entire retention period.
A general formula for estimating storage requirements is: [Daily Ingest] × [Total Retention Days] × 120%. This estimation ensures sufficient storage for all logs while accounting for traffic spikes and preventing storage depletion.
Additionally, other Graylog features that may require extra storage include warm tier storage (for lower-cost, long-term searchable storage) and the Data Lake (for compliance and historical log retention).
Conventional Deployment
A conventional deployment is the recommended architecture for most larger scale production environments, especially those with high log volumes or multiple Graylog users. This setup distributes Graylog components across multiple nodes, ensuring high availability, scalability, and fault tolerance.
The diagram below provides a visual representation of this architectural model, demonstrating its components, data flow, resource allocation, hardware, and storage requirements.
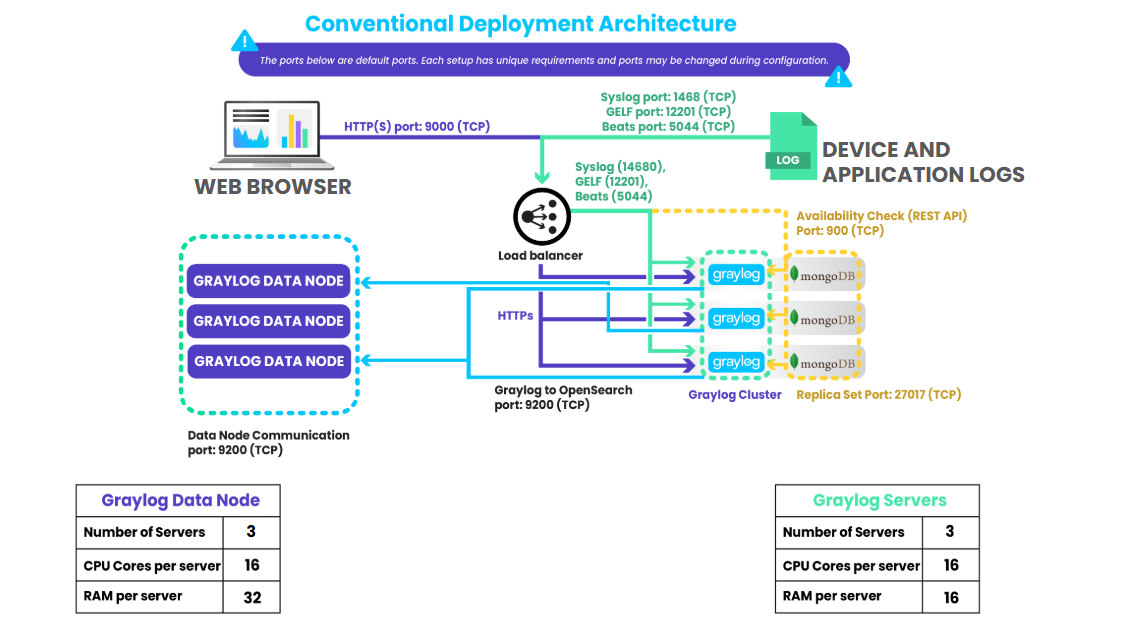
Some of the key characteristics of a Conventional deployment include:
-
High Availability: Redundancy ensures that log ingestion and processing continue even if one node fails.
-
Scalability: Additional nodes can be added easily to handle increased log volumes or user demands.
-
Performance Optimization: Graylog Data Nodes and MongoDB can be distributed and scaled independently.
Deployment Considerations
A conventional deployment requires careful planning of network configurations, resource allocation, and hardware sizing. You should also plan for monitoring and maintaining the cluster to ensure continued performance and uptime.
Message Storage
Graylog has two key components that require additional storage configuration: the message journal and Data Node index storage.
Message Journal
The message journal temporarily holds incoming messages before they are processed. By default, it is configured to store up to 5GB of messages or 12 hours of data.
For optimal performance, it is recommended to store the message journal on high-speed storage, such as solid state drives (SSDs), and allocate storage capacity equivalent to 3 to 5 times your daily data ingestion to ensure efficient processing and log retention.
For more details on configuring the message journal, refer to the Graylog Server Configuration documentation.
Data Node Index Storage
The Data Node index storage is where hot-tier message data is stored. It must have enough capacity to store logs for the entire retention period.
A general formula for estimating storage requirements is: [Daily Ingest] × [Total Retention Days] × 120%. This estimation ensures sufficient storage for all logs while accounting for traffic spikes and preventing storage depletion.
Additionally, other Graylog features that may require extra storage include warm tier storage (for lower-cost, long-term searchable storage) and the Data Lake (for compliance and historical log retention).
Custom Deployment
A Custom Graylog deployment is designed for Enterprise-scale environments handling larger log volumes. This architecture involves multiple Graylog servers, Data Nodes, and MongoDB instances to provide high availability, fault tolerance, and horizontal scalability. It is the most robust option for organizations with demanding log management requirements.
Some of the key characteristics of a Custom deployment include:
-
Distributed Architecture: Separate components (Graylog servers, MongoDB, and Graylog Data Nodes) can reside on many different physical or virtual machines, reducing bottlenecks.
-
Replication: Cross-datacenter replication can be configured for disaster recovery and geographic distribution.
Deployment Considerations
Deploying Graylog at scale requires expertise in configuring, managing, and maintaining distributed systems. Leveraging orchestration tools such as Ansible or Docker can simplify deployment and reduce operational overhead.
Security is a critical aspect of any Graylog architecture. Enforcing role-based access control (RBAC) and securing data transmission with TLS/SSL helps prevent unauthorized access. Additionally, encrypting log data both at rest and in transit ensures the protection of sensitive information.
Cost considerations are also essential, as large-scale deployments incur expenses related to hardware, software, and personnel. Careful planning is necessary to balance costs with performance and availability, ensuring efficient resource utilization without compromising system reliability.
Finally, backup and disaster recovery strategies are vital for maintaining a resilient Graylog environment. Regular backups of MongoDB, OpenSearch indices, and Graylog configuration files should be performed, with periodic testing of restoration procedures to guarantee system recoverability in the event of failure.
Message Storage
Graylog has two key components that require additional storage configuration: the message journal and Data Node index storage.
Message Journal
The message journal temporarily holds incoming messages before they are processed. By default, it is configured to store up to 5GB of messages or 12 hours of data.
For optimal performance, it is recommended to store the message journal on high-speed storage, such as solid state drives (SSDs), and allocate storage capacity equivalent to 3 to 5 times your daily data ingestion to ensure efficient processing and log retention.
For more details on configuring the message journal, refer to the Graylog Server Configuration documentation.
Data Node Index Storage
The Data Node index storage is where hot-tier message data is stored. It must have enough capacity to store logs for the entire retention period.
A general formula for estimating storage requirements is: [Daily Ingest] × [Total Retention Days] × 120%. This estimation ensures sufficient storage for all logs while accounting for traffic spikes and preventing storage depletion.
Additionally, other Graylog features that may require extra storage include warm tier storage (for lower-cost, long-term searchable storage) and the Data Lake (for compliance and historical log retention).
Further Reading
Explore the following additional resources and recommended readings to expand your knowledge on related topics:
