There are a few rules of thumb when scaling resources for Graylog:
-
Graylog nodes should have a focus on CPU power. These also serve the user interface to the browser.
-
Elasticsearch/OpenSearch nodes should have as much RAM as possible and the fastest disks you can get. Everything depends on I/O speed here.
-
MongoDB is storing meta information and configuration data and doesn’t need many resources.
Also keep in mind that ingested messages are only stored in Elasticsearch. If you have data loss in the Elasticsearch cluster, the messages are gone - except if you have created backups of the indices.
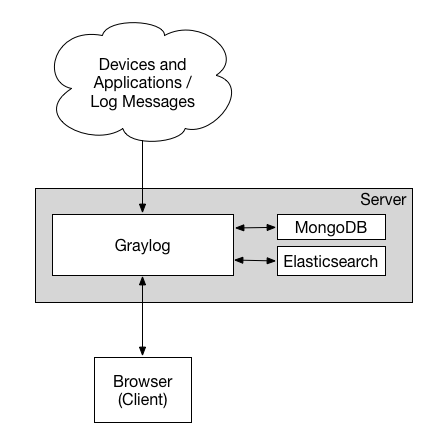
Minimum Setup
This is a minimum Graylog setup that can be used for smaller, non-critical, or test setups. None of the components are redundant, and they are easy and quick to setup.
Bigger Production Setup
This is a setup for bigger production environments. It has several Graylog nodes
behind a load balancer distributing the processing load.
The load balancer can ping the Graylog nodes via
on
the Graylog REST API to check if they are alive and take dead nodes out of the cluster.
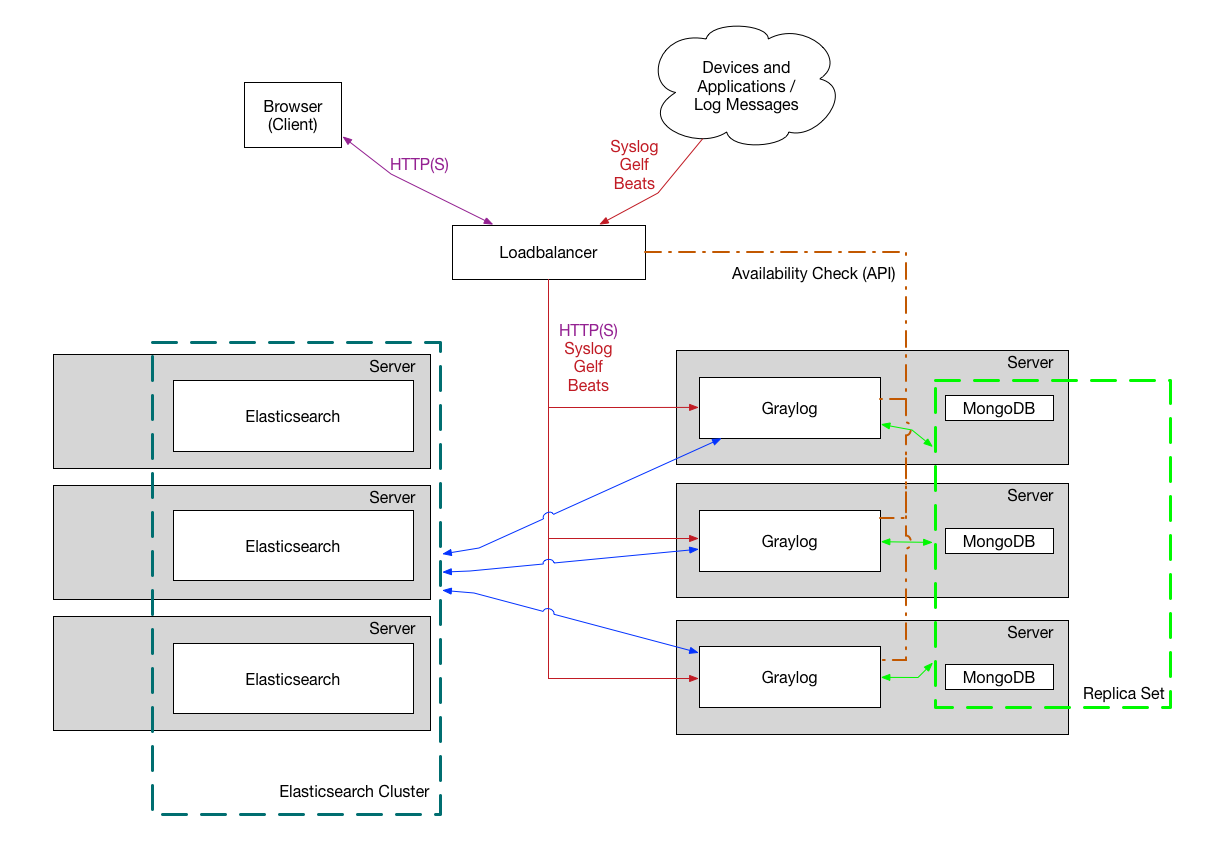
How to plan and configure such a setup is covered in our Multi-node Setup
guide.
Some guides on the Graylog Marketplace also offer
some
ideas how you can use RabbitMQ
(AMQP) or Apache
Kafka to add some queuing to your setup.