The Operations Output Framework is a structured approach that enables message forwarding from Graylog clusters to external systems. Messages are forwarded via a variety of methods; these include raw network text, formatted network messages, and STDOUT. Framework-based outputs can be configured to use processing pipelines to filter, modify, and enrich the outbound messages.
The Operations Output Framework provides several outputs for various network transport types. Messages stay in the on-disk journal until the output can successfully send the data to the external receiver.
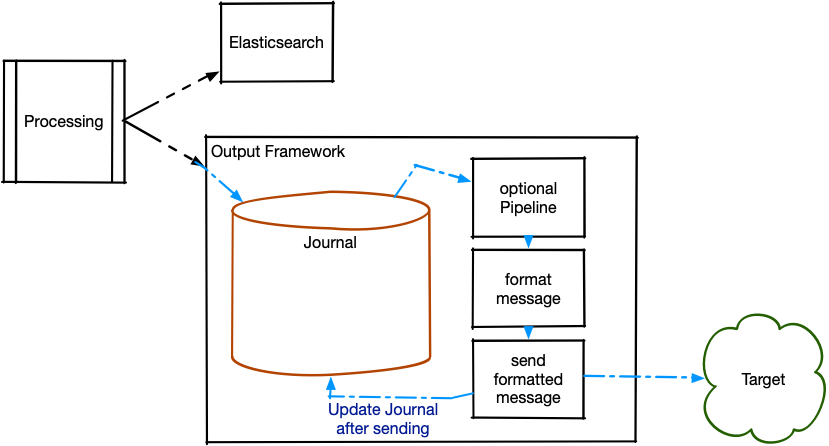
Once messages have been written to the journal, you can run them through a processing pipeline to modify or enrich the logs with additional data. You can transform the message contents or filter out any logs before sending them.
The processing pipeline converts the output payload to the desired format and then sends it using the selected transport protocol. Messages arrive at the Output Framework in the source cluster once they have completed processing and have been written to OpenSearch.
On-Disk Journal
The Output Framework is equipped with an on-disk journal, which immediately persists messages received from the Graylog output system to the disk and then sends the messages to the external receiver. The Output Framework continually receives messages and queues them, even if the external receiver is temporarily unavailable due to network issues.
The journal data is stored in the directory controlled by the data_dir value in the Graylog configuration file. Journal data for framework outputs is stored in <data_dir>/stream_output/<OutputID>. As with the output base path and the input journal, the Output Framework uses a separate partition for journals to ensure journal growth does not impact overall system performance.
Hint: Maximum Journal Size is a soft-limit configuration for Operations outputs; the on-disk journal may grow larger. To guarantee journal data is cleaned up in a timely fashion, adjust the Maximum Journal Message Age and Journal Segment Age configuration values. Unsent messages in the journal are purged once they are older than the maximum journal message age.
Select an Operations Output
All Operations outputs first write messages to an on-disk journal in the Graylog cluster. Each output type then sends these messages in a particular format, as explained below:
-
Operations TCP/UDP Raw/Plaintext Output
- Sends messages as UTF-8 encoded plain text to the configured TCP endpoint (IP address and port).
-
Operations TCP/UDP Syslog Output
- Sends formatted messages as the
MSGportion of a standard syslog message per section 6.4 of the Syslog specification. The syslog message is sent to the configured TCP endpoint (IP address and port).
- Sends formatted messages as the
-
Operations Google Cloud BigQuery Output
- The Output Framework converts the message’s key-value pairs into a new row for insertion into the specified Google BigQuery table.
-
Operations STDOUT Output
- Displays formatted messages on the system’s console. This is primarily included as a debugging tool for pipeline changes.
Set Up a New Output
To set up a new output, follow the relevant output documentation and select one of the Operations outputs as listed in the above section.
Configure an Output
The Operations Output Framework can process messages at very high throughput rates. Throughput is affected by many hardware factors, such as CPU clock speed, number of CPU cores, available memory, and network bandwidth. As noted in Outputs, default values for configuration options are populated by Graylog according to output type selected; however, several notable Output Framework configuration options can tune performance for throughput requirements and environments depending on your preferences and requirements.
-
Send Buffer Size
- The number of messages the output can hold in its buffer while waiting to be written to the Journal. This is on the outgoing side of the Journal. If you increase the number of formatters/ senders you should also increase the send buffer size.
-
Concurrent message processing pipelines
- The number of pipeline instances that are allowed to run at any given time.
- If set to 0, pipeline execution is skipped, even if a pipeline is selected from the pipeline drop-down.
-
Concurrent output payload formatters
- The number of formatter instances that are allowed to run at any given time.
- If this is set to 0, the output will fail.
-
Concurrent message senders
- The number of sender instances that are allowed to run at any given time. If this is set to 0, the output will fail.
- These allocate threads to the pieces that prepare messages to be sent and sends them. If there is an output backup problem, you may increase this number to get more throughput. You should first determine whether your receiver can handle the extra load.
- Increase the number of concurrent formatters/senders if your journal is overloaded with a disproportionate amount of messages.
-
Journal Segment Size
- The journal segment file soft maximum size. This can be adjusted to aid in the retention of messages.
-
Journal Segment Age
- The maximum amount of time journal segments are retained if there is storage to do so.
-
Maximum Journal Size
- The maximum size of the journal.
-
Maximum Journal Message Age
- The maximum time that a message is stored in the disk journal.
-
Journal Message Flush Interval
-
Controls how often the journal content is forced to disk from memory.
-
-
Journal Buffer Size
-
The journal buffer is where messages are stored before they are written to the journal.
-
If this is increased, the amount of memory used will increase and it will take longer for backed up messages to be dropped. You should carefully reconsider the size of your journal and the resources allocated to sending out messages before increasing the Journal Buffer Size.
- This value must be a power of two.
-
-
Journal Buffer Encoders
- The number of concurrent encoders for messages being written to the journal.
- Increasing these encoders would help if messages aren't flowing through the journal quickly.
-
Output Processing Pipeline
- The pipeline that processes all messages sent to the output.
-
Outbound Payload Format
- The format used for outgoing message payloads.
Configure the Outbound Payload
Before sending data out over the wire, Graylog formats the outgoing payload. These payload formatters translate log data from Graylog into the desired format. For Operations outputs, the following options for payload formatting are available during the process of setting up a new output:
-
Convert to JSON
-
If selected, the Output Framework will convert the message’s key-value pairs into a JSON object.
-
-
Use the
pipeline_outputfield-
The Output Framework will expect the pipeline to generate the outgoing payload and store it in the
pipeline_outputfield of the message, which can be accomplished in the pipeline by using theset_fieldbuilt-in function.
-
-
Use the
full_messagefield-
Some inputs support storage of the full received message in the
full_messagefield. When this output formatter is selected, the content'sfull_messageis used as the payload of the outgoing message. Messages without afull_messagefield or messages where the field is empty are ignored. More information on selecting this configuration option is available in the following section.
-
-
Pass-through Formatter
-
Previously known as the no-op formatter, the pass-through formatter is only intended for use with Google Cloud BigQuery output. This formatter was especially created to allow messages to utilize the Output Framework without generating a payload. It performs no operations on the message itself as the Google BigQuery output utilizes key value pairs from the message without any formatting required. If this formatter is used with any other output type, the payload will be empty.
-
Use the full_message Field to Set Up an Output
Operations outputs can be configured to use the full_message field. This option may be chosen for the purpose of troubleshooting, where access to the raw message is required.
1. Go to System > Inputs and locate the desired input.
2. Click on More Actions > Edit Input and select the Store full message option for each input.
3. Click Update input.
3. Set up a new output.
4. Set Outbound Payload Format to Use the full_message field.

Add a Pipeline to Outgoing Messages
Pipelines allow you to define rules that regulate the order in which message processing steps are executed. When creating or editing an Operations output, you can opt to add a processing pipeline on each message coming from the source stream. The built-in function route_to_stream causes a message to be routed to a particular stream. After the routing occurs, the pipeline engine will look up and start evaluating any pipelines connected to that stream. This enables fine-grained control of the processing applied to messages.
An added pipeline can filter out incoming messages that are unwanted and unnecessary. For example, you can use a processing pipeline with Google Cloud BigQuery Outputs to prevent unwanted fields from being sent to the BigQuery table.
Pipelines can also be used to add data and modify the contents of the outgoing message or to enrich it with additional data. Please see the documentation on processing pipelines for further details.
To add a pipeline:
-
Go to System >Outputs.
-
Select the desired output type.
-
Click Launch new output.
-
Scroll to the bottom of the window.
-
Select a pipeline from the drop-down list and click Create output.
