The following article exclusively pertains to a Graylog Enterprise feature or functionality. To learn more about obtaining an Enterprise license, please contact the Graylog Sales team.
Archiving allows you to configure a retention period and automatically delete older messages. Configuring a retention period helps you to control the costs of storage in Elasticsearch and allows you to store data for long periods of time to comply with HIPAA, PCI, or other requirements.
The Archiving functionality archives log messages until you need to re-import them into Graylog for analysis. You can instruct Graylog to automatically archive log messages to compressed flat files on the local file system, or to an S3-compatible object storage, before retention cleaning kicks in and messages are deleted from Elasticsearch. Archiving works through a REST call or the web interface, if you don’t want to wait until retention cleaning happens. Flat files are vendor-agnostic, so your data is always accessible.
Here are your options to manage and maintain archived files:
- Move them to inexpensive storage or write them on tape.
- Print them out if you need physical access to these files.
- Move any selection of archived messages back into the Graylog archive folder, so that you can search through, and analyze, archived data through the web interface.
Installation
Archiving is part of the Graylog Operations plugin. Please check the Graylog Operations setup page for installation instructions.
Configuration
You can configure the Graylog Archive via the Graylog web interface without any configuration file changes.
In the web interface menu, navigate to "Enterprise/Archives" and click Configuration to adjust the configuration.
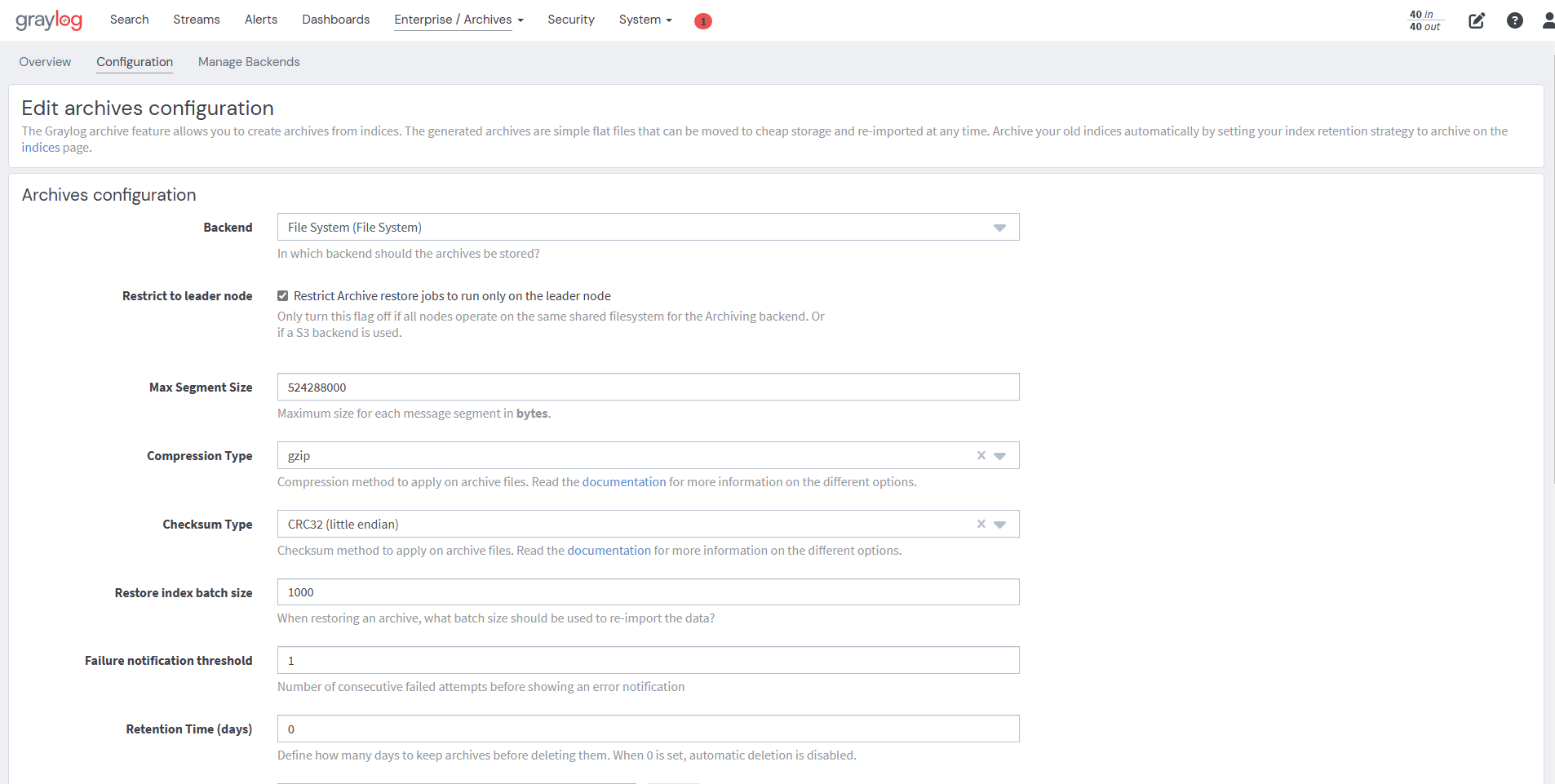
Archive Options
Here are the archive configuration options:
|
Name |
Description |
|---|---|
|
Backend |
Backend on the master node where the archive files will be stored. |
|
Max Segment Size |
Maximum size (in bytes) of archive segment files. |
|
Compression Type |
Compression type used to compress the archives. |
|
Checksum Type |
Checksum algorithm used to calculate the checksum for archives. |
|
Restore index batch size |
Elasticsearch batch size when restoring archive files. |
|
Streams to archive |
Streams included in the archive. |
Backends
The archived indices are stored in a backend. You can choose either type:
- File system
- S3
File System Backend
Initial server startup triggers the creation of a backend. Data is then stored in /tmp/graylog-archive.
S3 Archiving Backend
The S3 Archiving Backend can be used to upload archives to an AWS S3 object storage service and is built to work with AWS. AWS S3 is also compatible with other S3 implementations, like MinIO, CEPH, Digital Ocean Spaces, etc.
On the "Archive" page:
- Click the Manage Backends button on the top right.
- Click Create Backend under Archive Backends. This routes to Edit archive backend configuration options.
- Go to the Backend configuration section, and on the Backend Type dropdown, select S3.
- Fill in the fields that best suit your choice of archive.
|
Name |
Description |
|---|---|
|
Title |
A title to identify the backend. |
|
Description |
Description of the backend. |
|
S3 Endpoint URL |
Only configure this if not using AWS. |
|
AWS Authentication Type |
Choose access type from the dropdown menu. |
|
AWS Assume Role (ARN) |
An optional input for alternate authentication mechanisms. |
|
Bucket Name |
The name of the S3 bucket. |
|
Spool Directory |
Directory where archiving data is stored before it is uploaded. |
|
AWS Region |
Choose Automatic or configure the appropriate option. |
|
S3 Output Base Path |
Archives are stored under this path. |
AWS Authentication Type
Graylog provides several options for granting access. You can:
- Ude the Automatic authentication mechanism if you provide AWS credentials through your file system or process environment.
- Enter credentials manually.
AWS Assume Role (ARN)
ARN is typically used for allowing cross-account access to a bucket. See ARN for further details.
Spool Directory
The archiving process needs the spool directory to store some temporary data before it can be uploaded to S3.
Ensure that the directory is writable and has sufficient space for 10 times the Max Segment Size. Make adjustments with the form mentioned in Configuration.
AWS Region
If you are not using AWS, you do not need to configure AWS Region.
Select the AWS region where your archiving bucket resides. If you select nothing, Graylog will use the region from your file system or process environment, if available.
S3 Output Base Path
S3 Output Base Path is a prefix to the file name that works similarly to a directory. Configure this to help organize your data.
You can use the following variable to construct a dynamic value for each archive to give it structure:
|
Variable |
Description |
|---|---|
|
index-name |
Name of the index that gets archived. |
|
year |
Archival date year. |
|
month |
Archival date month. |
|
day |
Archival date day. |
|
hour |
Archival date hour. |
|
minute |
Archival date minute. |
|
second |
Archival date second. |
AWS Security Permissions
When writing AWS Security policies, make them as restrictive as possible. It is a best practice to enable specific actions needed by the application rather than allowing all actions.
These permissions are required for Graylog to successfully make use of the S3 bucket:
| Permission | Description |
|---|---|
| CreateBucket | Creates an S3 bucket. |
| HeadBucket | Determines if an action is useful and if you have permission to access it. |
| PutObject | Adds an object to a bucket. |
| CreateMultipartUpload | Initiates a multipart upload and returns an upload ID. |
| CompleteMultipartUpload | Completes a multipart upload by assembling previously uploaded parts. |
| UploadPart | Uploads a part in a multipart upload. |
| AbortMultipartUpload | Aborts a multipart upload. |
| GetObject | Retrieves objects from Amazon S3. |
| HeadObject | Retrieves metadata from an object without returning the object itself. |
| ListObjects | Returns some or all (up to 1,000) of the objects in a bucket with each request. |
| DeleteObjects | Enables you to delete multiple objects from a bucket using a single HTTP request. |
Activate Backend
Configure your bucket, and click Save.
This routes you back to the Edit archive backend configuration page.
To activate the backend, follow the instructions below.
- Click on the Configuration tab located in the top right-hand corner.
- Under the Backend dropdown menu, select the backend you want to activate.
- You can choose to change configurations or use the defaults provided.
- Click the green Update configuration button at the bottom of the screen.
- This will route you to the Archives screen.
Max Segment Size
When you archive an index, the archive job writes the data into segments. The Max Segment Size setting sets the size limit for each of these data segments to control the size of the segment files and process them with tools with a file-size limit.
Once the size limit is reached, a new segment file is started.
Example:
/path/to/archive/
graylog_201/
archive-metadata.json
archive-segment-0.gz
archive-segment-1.gz
archive-segment-2.gz
Compression Type
Archives are compressed with gzip by default, but you can switch to a different compression type.
The selected compression type significantly impacts the time it takes to archive an index. Gzip, for example, is slow but has a great compression rate. Snappy and LZ4 are quicker, but the archives are larger.
Here is a comparison between the available compression algorithms with test data.
|
Type |
Index Size |
Archive Size |
Duration |
|---|---|---|---|
|
gzip |
1 GB |
134 MB |
15 minutes, 23 seconds |
|
Zstandard |
1 GB |
225.2MB |
5min 55sec |
|
Snappy |
1 GB |
291 MB |
2 minutes, 31 seconds |
|
LZ4 |
1 GB |
266 MB |
2 minutes, 25 seconds |
Checksum Type
When Graylog writes archives, it also computes a CRC32 checksum over the files. You can select a different option to use a different checksum algorithm if needed.
To select the appropriate type of checksum, look to the use case. CRC32 and MD5 are quick to compute and are a reasonable choice to detect damaged files, but neither is suitable as protection against malicious changes in the files. Graylog also supports using SHA-1 or SHA-256 checksums, which can ensure the files were not modified, as they are cryptographic hashes.
The best way to choose a checksum type is to consider whether the necessary system tools to compute them later are installed (SHA-256 utility, for example), the speed of checksum calculation for larger files, and security considerations.
Restore Index Batch Size
The Batch Size setting controls the batch size for re-indexing archive data into Elasticsearch. When set to 1000,
Use this setting to control the speed of the restore process and how much of a load it will generate on the Elasticsearch cluster. The higher the batch size, the faster the restore will progress, and the more load will be put on your Elasticsearch cluster beyond the normal message processing.
Tune this carefully to avoid any negative impact on your message indexing throughput and search speed.
Streams To Archive
The Streams to Archive setting is included in the archive and allows you to archive only important data, rather than everything that is brought into Graylog.
Bulk Restore
Graylog 5.0 allows bulk restoring of archives, which can be useful in situations where extensive investigations or auditing requires searching across a larger time range.
-
To bulk restore archives in Graylog, navigate to the Graylog web interface and click on the Enterprise tab.
-
Select Archives from the dropdown menu.
-
Then, select the archives you intend to restore by clicking on the checkboxes, and click on the Bulk Actions button.
-
To complete, select Restore from the options list.
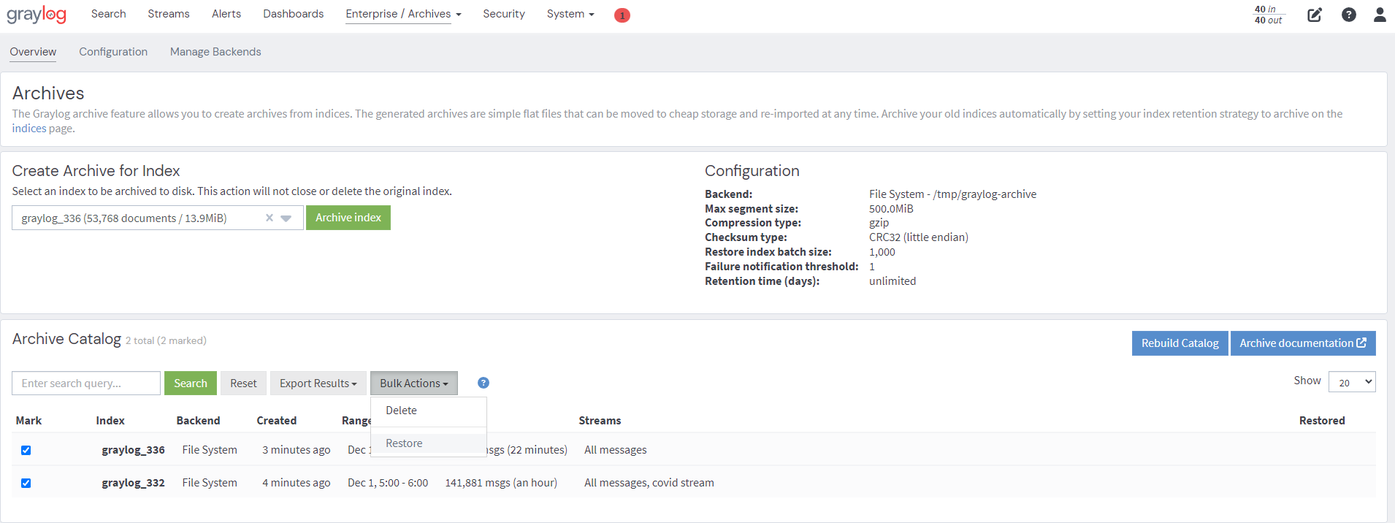
The selected archives will be displayed on the user interface after they have been restored.
Backends
You can use a backend to store archived data. Currently, Graylog only supports a single-file system backend type.
File System
The archived indices are stored in the Output base path directory. This directory needs to exist and be writable for the Graylog server process to store the files.
We recommend housing the Output base path directory on a separate disk or partition to avoid any negative impacts on message processing when the archive fills up a disk.
|
Name |
Description |
|---|---|
|
Title |
A title to identify the backend. |
|
Description |
A description for the backend. |
|
Output base path |
Directory path where the archive files are stored. |
Output base path
Use a simple directory path string or a template string as the output base path to build dynamic paths.
You can use a template string to store the archive data in a directory tree, which is based on the archival date.
Example:
# Template
/data/graylog-archive/${year}/${month}/${day}
# Result
/data/graylog-archive/2017/04/01/graylog_0
|
Name |
Description |
|---|---|
|
|
Archival date year (e.g. “2017”). |
|
|
Archival date month (e.g. “04”). |
|
|
Archival date day (e.g. “01”). |
|
|
Archival date hour (e.g. “23”). |
|
|
Archival date minute (e.g. “24”). |
|
|
Archival date second (e.g. “59”). |
|
|
Name of the archived index (e.g. “graylog_0”). |
Index Retention
Graylog uses configurable index retention strategies to delete old indices. By default, indices can be closed or deleted if you have more than the configured limit.
The Graylog Archive offers a new index retention strategy that you can configure to automatically archive an index before closing or deleting it.
Index retention strategies can be configured in the system menu under System/Indices. Select an index set, and click Edit to change the index rotation and retention strategies.
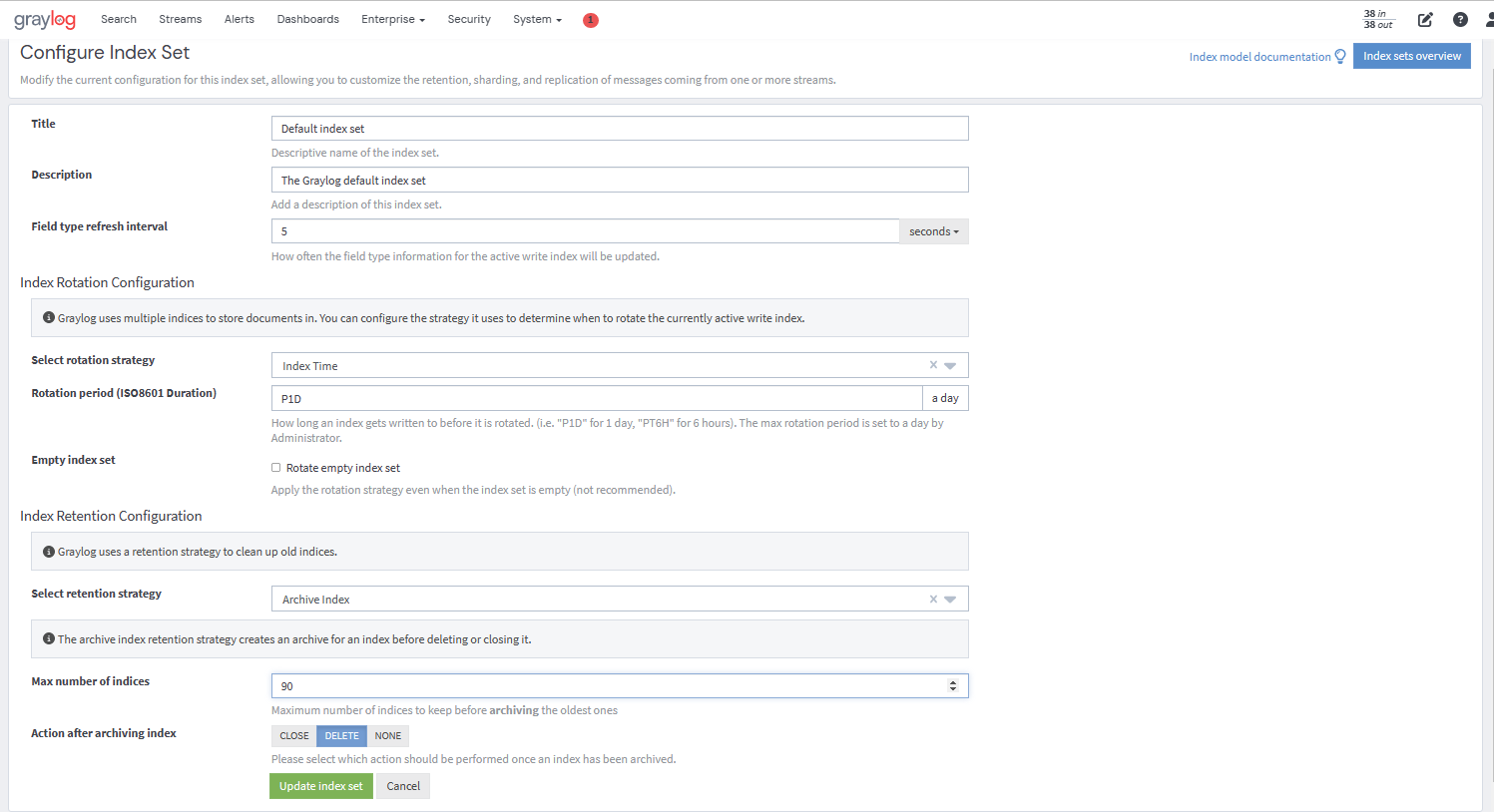
As with the regular index retention strategies, you can configure a maximum number of Elasticsearch indices. When there are more indices than the configured limit, the oldest indices are archived in the backend and closed or deleted. You can also decide to do nothing (NONE ) after archiving an index. In that case, no cleanup of old indices will happen, and you can manage the archive yourself.